
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 공룡책
- go
- C언어
- OS
- BOJ
- 리듬게임
- 백준
- gui
- LOB
- 알고리즘
- vim-go
- JUCE
- a tour of go
- tour of go
- Docker
- JUCE 튜토리얼
- JUCE라이브러리
- C++ gui 라이브러리
- C++ library
- 프로그래밍
- Nebula
- 연결리스트
- 자료구조
- go channel
- 운영체제
- C++
- 코딩
- c++ heap
- C++ gui
- JUCE library
- Today
- Total
CafeM0ca
[공룡책] 챕터5 CPU 스케쥴링 본문
챕터5 CPU 스케줄링
CPU가 놀고 있으면 ready queue에서 프로세스를 뽑아서 실행시킨다.
이 작업은 CPU 스케쥴러가 담당한다.
ready queue는 우선순위 큐, 트리, 단방향 링크드 리스트로 구현될 수 있다.
ready queue에는 PCB가 들어 있다.
CPU burst : 프로세스가 cpu를 사용하는 시간
dispatcher
CPU 스케줄링의 포함된 기능중 디스패처가 있다.
디스패처는 CPU 스케줄러가 선택한 프로세스에 cpu 코어를 제어하는 모듈이다.(?)
- 한 프로세스에서 다른 프로세스로 context을 교환하는 일
- 사용자 모드로 전환하는 일
- 프로그램을 다시 실행하기 위해 사용자 프로그램의 알맞은 위치로 jumping하는 일
디스패처는 모든 context switch에서 발생하므로 최대한 빨라야한다.
디스패처 레이턴시는 프로세스를 정지하고 그 상태를 PCB에 저장하고 다음에 실행할 프로세스 PCB를 복구하고 프로세스를 실행하는 시간을 의미한다.

스케줄링 기준
- CPU utilization : CPU 사용율. 작은 작업은 40%, 큰작업은 90%까지
- throughput : 처리량
- turnaround time : 총 처리 시간
- waiting time : 대기시간
- response time : 응답 시간
스케줄링 알고리즘
- FCFS(First-come, First-served) : 먼저 오는 순서대로 처리
- SJF(shortest-job-first) : 작업시간이 작은 순서대로 처리
- Priority scheduling : 우선순위가 있는 순서대로 처리
- Round Robin : 시분할 시스템에서 사용함. 프로세스마다 제한 시간만큼 사용하고 ready queue에 다시 들어감. 시간할당량이 너무 적으면 context-switch 하는 시간이 더 많이 들고, 반대로 너무 크면 FCFS로 전략해버리니 CPU 버스트의 80%보다 작은게 좋다.
- 다단계 큐 스케줄링(multilevel queue scheduling) : 프로세스들을 그룹으로 나눌 수 있는 경우 그룹별로 우선순위를 정하고 해당 그룹에 있는 작업 먼저 처리함. 우선순위가 낮으면 영원히 순서가 안올 수 있어서 기아상태에 빠질 수 있음.
- 다단계 피드백 큐 스케줄링 : 다단계 큐에서는 프로세스간 그룹 이동이 없는데, 다단계 피드백 큐에서는 프로세스간 그룹 이동이 존재함. 따라서 기아 상태를 예방할 수 있음.
- 큐의 개수
- 각 큐를 위한 스케줄링 알고리즘
- 한 프로세스를 우선순위가 높은 큐로 올리는 시기 결정방법
- 한 프로세스를 우선순위가 낮은 큐로 내리는 시기 결정방법
- 프로세스가 큐에 할당할지 지정하는 방법
- 다단계 피드백 큐 스케줄러는 아래 매개변수로 정의된다.
스레드 스케줄링
user-level과 kernel-level 스레드를 구분하는 하나의 방법으로 어떻게 스케줄 되는지를 보는 방법이 있다. 다대일과 다대다 모델에서 유저 레벨 스레드는 LWP에서 스케줄된다. 이 구조는 동일한 프로세스에 속한 스레드 사이에서 CPU를 경쟁하기 때문에 PCS(process-contention scope)로 알려져 있다.
스레드 라이브러리가 LWP에서 스케줄 된다고 실제로 CPU 상에서 스케줄 되는게 아니다.
커널레벨 스레드가 CPU에 스케줄 되기 위해서 커널은 SCS(system-contention-scope)를 사용한다. SCS 스케줄링에서 CPU에 대한 경쟁은 시스템 상의 모든 스레드 사이에서 일어난다.
window xp, solaris, linux 같은 일대일 모델을 사용하는 시스템은 SCS만 사용하여 스케줄한다.
멀티프로세서 스케줄링
cpu를 여러개 사용할 수 있으면 load sharing(부하 공유)이 가능하지만 스케줄링 복잡성은 더욱 증가한다.
멀티 프로세스 시스템의 CPU 스케줄링에 관한 한 가지 접근 방법은 master server를 놓고 하나의 프로세서가 모든 스케줄링 결정과 입출력 처리, 다른 시스템의 활동을 처리하는 방법이 있다. 다른 프로세스는 우리가 작성한 코드를 실행한다.
- 장점
- 이러한 비대칭 멀티프로세싱은 한 코어가 시스템 자료구조에 접근하여 자료 공유의 필요성을 감소할 수 있기 때문에 간단함
- 단점
- 하항식 접근은 마스터 서버가 병목이 생기면 시스템 전체에 문제가 생길 수 있다.
SMP
멀티프로세서를 지원하는 가장 쉬운 접근 방법은 symmetric multiprocessing(SMP)이다. 각 프로세서가 스스로 스케쥴링하는 방법이다. 스케쥴링은 각 프로세서의 스케쥴러가 ready큐을 검사하고 실행할 스래드를 선택하는 식으로 진행한다. 스레드를 구성하기 위한 두 가지 전력을 제공한다.
- 모든 스레드는 공통 ready 큐를 사용하는 방법
- 레이스 컨디션이 shared ready큐에서 발생할 수 있음.
- 각 프로세서는 각 스레드의 private 큐 갖고 있어서 이를 사용하는 방법
- 아래는 1,2번에 대한 예시
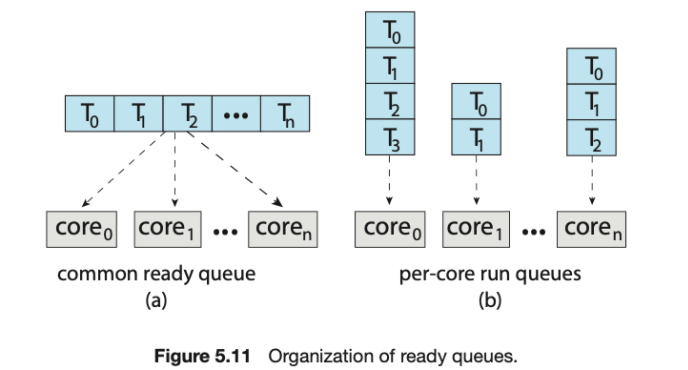
멀티코어 프로세서
하나의 물리적 칩 안에 여러 개의 프로세서 코어를 장착하는 것을 멀티코어 프로세서라 한다.
각 코어는 상태를 유지하기 위한 레지스터 집합을 갖고 있음
SMP 시스템은 각 프로세서가 자신의 물리 칩을 갖는 시스템에 비해 속도가 빠르고 적은 전력을 소모함.
memory stall(메모리 멈춤)
다중코어 프로세서에서 스케줄링중에 프로세서가 메모리를 접근 할 때 데이터가 가용되길 기다리면서 많은 시간을 허비하는 것.
캐시 미스 등의 여러 원인이 있음.
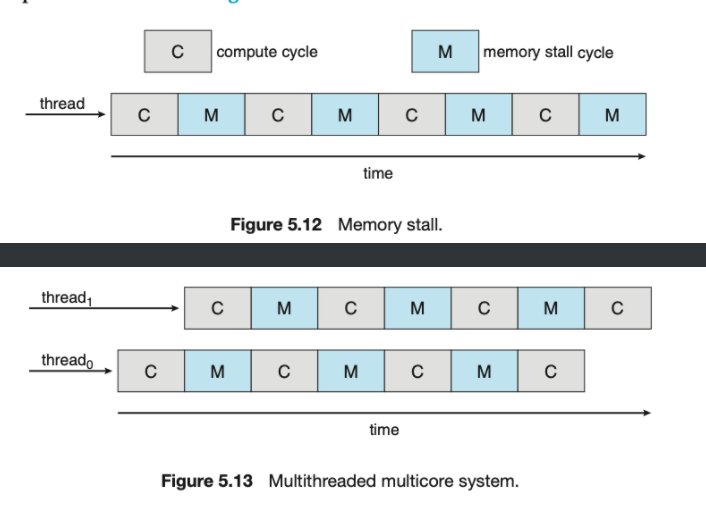
Figure 5.12에서는 메모리를 사용하고 가용을 기다리는 시간을 허비함
Figure 5.13에서는 멀티스레딩을 지원하는 멀티코어 시스템에서 서로 교차적으로 처리
coarse-grained(크게-나눔)
메모리 멈춤과 같은 현상이 발생할 때 까지 한 프로세서에서 스레드를 처리함.
대기시간이 길어지면 다른 프로세서에서 처리
프로세서를 옮기는 과정에서 명령어 파이프라인이 완전히 정리되어야 해서 스레드 간 교환 비용이 큼
fine-graine(잘게-나눔)
크게-나눔과 비슷하며 스레드 교환 회로가 포함되어 있어서 스레드 간 교환 비용이 적음
CMP(cip multithreading)
운영체제 관점에서 각 하드웨어 스레드는 instruction 포인터 및 레지스터 셋과 같은 아키텍처 상태를 유지하므로 소프트웨어 스레드를 실행하는데 사용할 수 있는 논리 CPU로 나타낸다.
프로세서는 4개의 컴퓨팅 코어를 갖고 있고 각 코어는 2개의 하드웨어 스레드를 갖고 있다.
운영체제 관점에서는 8개의 논리 CPU로 보이게 된다.
PCS : 스레드는 같은 프로세스를 쓰니까 같은 프로세스 안에서 스레드 경쟁
SCS: 운영체제가 커널스레드를 스케쥴링 하는데 사용.
다대일, 다대다에서 PCS, SCS를 비교하면 다른데, 일대일 모델에선 PCS,SCS는 똑같다.
'OS > 공룡책' 카테고리의 다른 글
| [공룡책] 챕터7 동기화 예시 문제풀이 (0) | 2021.03.05 |
|---|---|
| [공룡책] 챕터7 동기화 예시 (0) | 2021.03.05 |
| [OS] 공룡책 챕터4 연습문제 (0) | 2021.01.22 |
| [OS] 공룡책 Chapter4 스레드 (0) | 2021.01.21 |
| [OS] 공룡책 Chapter 3 연습문제 풀이 10th edition (0) | 2021.01.14 |


